1. Longest Increasing Subsequence
Some of this material is borrowed from Jeff Erickson’s chapters on Recursion, Backtracking, and Dynamic Programming. In particular, the (very nice) analogy with traffic lights is from Erickson. Check them out for a more detailed comparison between recursive and memoized implementations. Thanks to Arya for pointing out a correction.
The Problem
For any sequence Q, a subsequence of Q is another sequence obtained from Q by deleting zero or more elements, without changing the order of the remaining elements; the elements of the subsequence need not be contiguous in Q.
For example, when you drive down a major street in any city, you drive through a sequence of intersections with traffic lights, but you only have to stop at a subsequence of those intersections, where the traffic lights are red. If you’re very lucky, you never stop at all: the empty sequence is a subsequence of Q. On the other hand, if you’re very unlucky, you may have to stop at every intersection: Q is a subsequence of itself.
Here are some examples:
BOATis a subsequence ofBOX-OF-CHOCOLATES.OOFis a subsequence ofBOX-OF-CHOCOLATES, butOO-Fis not.O-O-OOLAis a subsequence ofBOX-OF-CHOCOLATES, butFOXis not.FOOLandBHOLAare a subsequences ofBOX-OF-CHOCOLATES, butLAXandBETAare not.
Now suppose we are given a sequence of integers, and we need to find the length of a longest subsequence whose elements are in increasing order:
- the input is an integer array A[1 .. n], and
- we need to compute the length of a longest possible sequence of indices 1 \leqslant i_1<i_2<\cdots<i_{\ell} \leqslant n such that A\left[i_k\right]<A\left[i_{k+1}\right] for all k.
We will use LIS to refer to the phrase longest increasing subsequence. Note that there may be multiple increasing subsequences, and even multiple choices for increasing subsequences that are the longest. The approaches below that work correctly to find the length of a LIS are easily adaptable to finding a LIS as well.
The Solution — Take 0 (a dead end)
The Solution — Take 1 (building on the bad take)
Note that computing T[i,j] involves pinging two entries: T[i,j+1] and T[j,j+1]. So as long as all T[\star,j+1] entries are computed before we get to T[i,j], then we are covered.
Recall that the base case directly captures all entries of the form T[\star,n], and one valid sequence of comptuations would involve working our way backwards along the second dimension: i.e, compute T[\star,n-1], T[\star,n-2],\cdots, and so on.
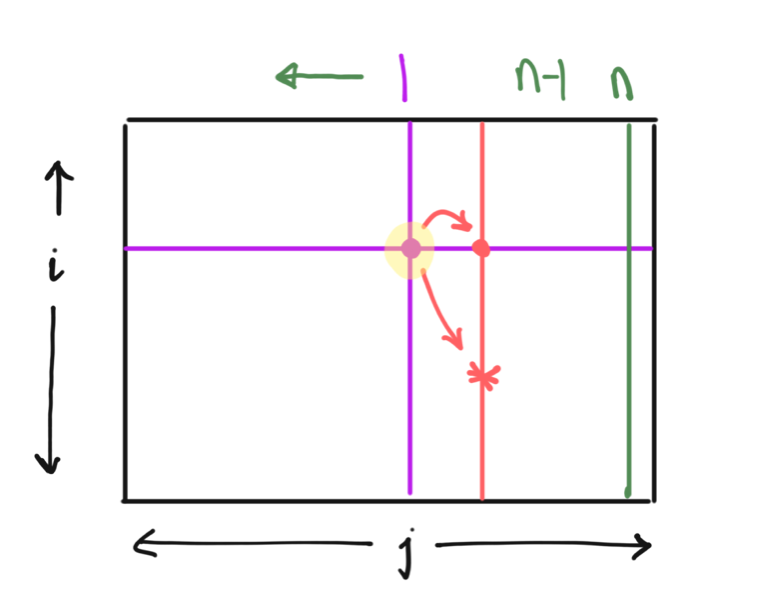
The Solution — Take 2 (a different approach)
Time and Space Complexity
For the first approach:
- We filled out O(n^2) entries at O(1) cost each, so the overall running time of the algorithm is O(n^2).
- We store O(n^2) entries, although with a careful implementation the storage can be limited to O(n).
For the second approach:
- We filled out O(n) entries at O(n) cost each, so the overall running time of the algorithm is O(n^2) again.
- We store O(n) values.
Correctness
The correctness of the computations of the T-values specified by both approaches above is implicit in the design of the recurrence. However, we provide an explicit proof for the second approach here. The proof of correctness for most of the other recurrences that we will discuss can be established with a similar approach in spirit and is left as an exercise.
Theorem. Let T[i] be given by:
T[i] = 1 + \max_{\{j | j > i, A[j] > A[i]\}} T[j], \text{ for any } i \in [n],
and let O[i] denote the length of a LIS in S_i. Then T[i] = O[i].
Proof.
Part 1. The DP stores a value that is achievable.
First, let us show that O[i] \geqslant T[i], that is, there is an subsequence of length T[i] that begins at A[i]. We prove this by backward induction over i.
The base case. T[n] = 1, and this is witnessed by the subsequence \{A[n]\}.
The induction step. If \{j | j > i, A[j] > A[i]\} = \emptyset, then T[i] = 1 and this is witnessed by the subsequence \{A[i]\}.
Otherwise, Let j^\star be the index that witnesses the \max value (if there are multiple indices that fit this bill, choose any). Note that j^\star > j. By the induction hypothesis, there is an subsequence of length T[j^\star] that begins at A[j^\star]. Prepend to this subsequence the value A[i], this is clearly an increasing subsequence of length 1 + T[j^\star], and we are done.
Part 2. The value computed by the DP cannot be beaten.
First, let us show that O[i] \leqslant T[i], that is, the length of any longest subsequence in S_i is at most T[i]. We prove this by backward induction over i.
The base case. O[n] = 1, and T[n] = 1, so there is nothing to prove.
The induction step. Here we proceed by contradiction. Suppose there is a subsequence (say \sigma^\star) in S_i whose length is k \geqslant T[i] + 1.
Consider the tail of \sigma^\star, that is, the entire subsequence with the first value — i.e, A[i] — omitted. Denote this subsequence by \sigma.
Note that \sigma has k-1 elements. Suppose the first element of \sigma is A[\ell]. Then \sigma \in S_\ell. Note also that \ell > i and A[\ell] > A[i], so T[\ell] \geqslant k-1 (by the induction hypothesis). Thus:
T[i] = 1 + \max_{\{j | j > i, A[j] > A[i]\}} T[j] \geqslant 1 + T[\ell] \geqslant 1 + (k-1) = k \geqslant T[i] + 1,
a contradiction.
Footnotes
Indeed, since we already have a kickstart at the fragment T[n], if we can figure out a way of recovering the value of T[i] assuming knowledge of T[j] for j > i, then we are done: we can use this method to go backwards starting from T[n] all the way back to T[1].↩︎

